Python Redis使用介绍
redis 是一个 Key-Value 数据库,Value 支持 string(字符串),list(列表),set(集合),zset(有序集合),hash(哈希类型)等类型。
Redis安装
略。
Redis启动界面如下:
可在redis.conf配置文件中,配置redis端口与密码
1 | 18570:C 1 Nov 11:45:53.072 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo |
Python3和Redis库安装
1 | [root@laosanxin redis-4.0.11]# yum install python3 |
1 | [root@laosanxin redis-4.0.11]# python3 -m pip install redis |

测试是否安装成功: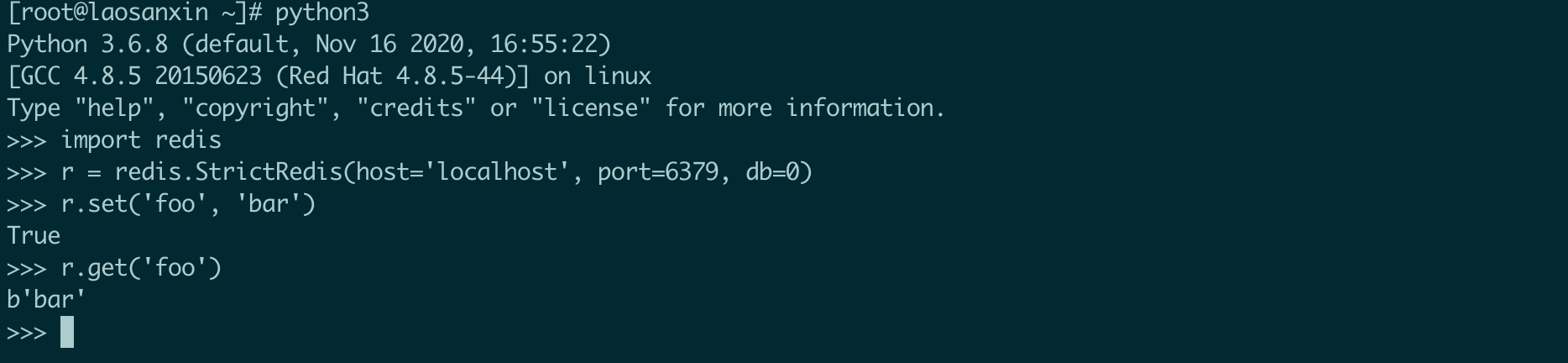
redis 提供两个类 Redis 和 StrictRedis, StrictRedis 用于实现大部分官方的命令,Redis 是 StrictRedis 的子类,用于向后兼用旧版本。
redis 取出的结果默认是字节,我们可以设定 decode_responses=True 改成字符串。
example:
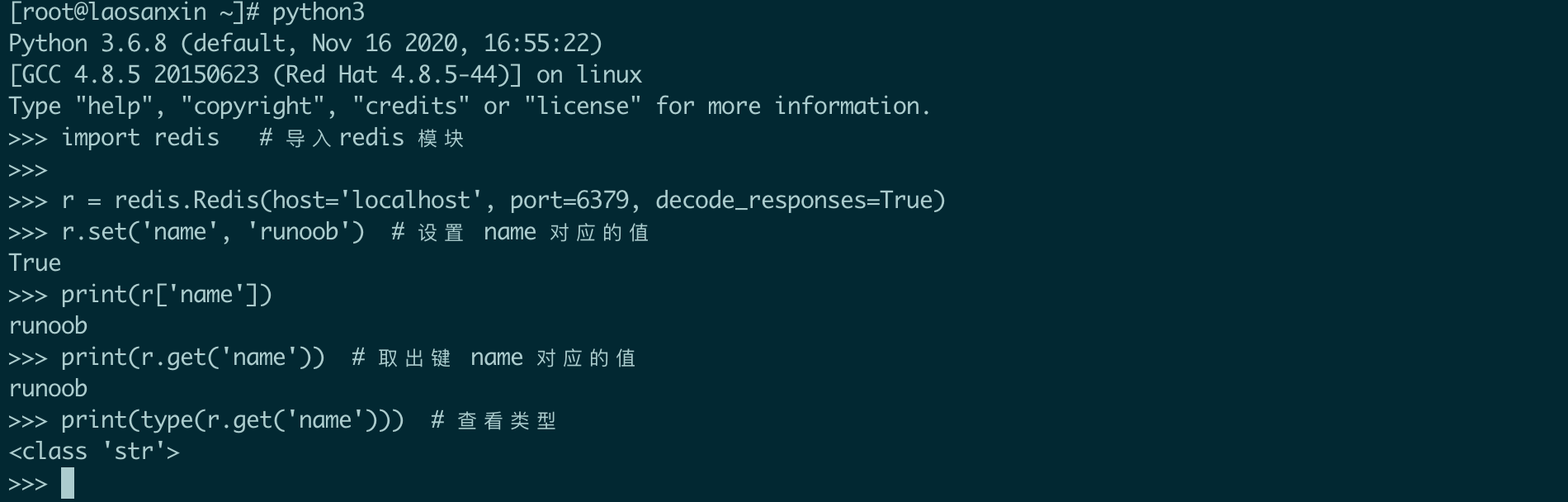
连接池
redis-py 使用 connection pool 来管理对一个 redis server 的所有连接,避免每次建立、释放连接的开销。
默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数 Redis,这样就可以实现多个 Redis 实例共享一个连接池。
1 | import redis # 导入redis 模块 |
redis 基本命令 String
et(name, value, ex=None, px=None, nx=False, xx=False)
在 Redis 中设置值,默认,不存在则创建,存在则修改。
参数:
ex - 过期时间(秒)
px - 过期时间(毫秒)
nx - 如果设置为True,则只有name不存在时,当前set操作才执行
xx - 如果设置为True,则只有name存在时,当前set操作才执行
1.ex - 过期时间(秒) 这里过期时间是3秒,3秒后p,键food的值就变成None
应用场景 – 页面点击数
假定我们对一系列页面需要记录点击次数。例如论坛的每个帖子都要记录点击次数,而点击次数比回帖的次数的多得多。如果使用关系数据库来存储点击,可能存在大量的行级锁争用。所以,点击数的增加使用redis的INCR命令最好不过了。
当redis服务器启动时,可以从关系数据库读入点击数的初始值(12306这个页面被访问了34634次)
1 | r.set("visit:12306:totals", 34634) |
每当有一个页面点击,则使用INCR增加点击数即可。
1 | r.incr("visit:12306:totals") |
页面载入的时候则可直接获取这个值
1 | print(r.get("visit:12306:totals")) |
redis 基本命令 hash
单个增加–修改(单个取出)–没有就新增,有的话就修改
hset(name, key, value)
name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
参数:
name - redis的name
key - name对应的hash中的key
value - name对应的hash中的value
注:hsetnx(name, key, value) 当name对应的hash中不存在当前key时则创建(相当于添加)
1
2
3
4
5
6
7
8
9
10
11
12
13import redis
import time
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hset("hash1", "k1", "v1")
r.hset("hash1", "k2", "v2")
print(r.hkeys("hash1")) # 取hash中所有的key
print(r.hget("hash1", "k1")) # 单个取hash的key对应的值
print(r.hmget("hash1", "k1", "k2")) # 多个取hash的key对应的值
r.hsetnx("hash1", "k2", "v3") # 只能新建
print(r.hget("hash1", "k2"))
批量增加(取出)
hmset(name, mapping)
在name对应的hash中批量设置键值对
参数:
- name - redis的name
- mapping - 字典,如:{‘k1’:’v1’, ‘k2’: ‘v2’}
取值查看–分片读取
hscan(name, cursor=0, match=None, count=None)
增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆参数:
- name - redis的name
- cursor - 游标(基于游标分批取获取数据)
- match - 匹配指定key,默认None 表示所有的key
- count - 每次分片最少获取个数,默认None表示采用Redis的默认分片个数
redis基本命令 list
增加(类似于list的append,只是这里是从左边新增加)–没有就新建
lpush(name,values)
在name对应的list中添加元素,每个新的元素都添加到列表的最左边
1
2
3
4
5
6
7
8import redis
import time
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.lpush("list1", 11, 22, 33)
print(r.lrange('list1', 0, -1))
redis基本命令 set
新增
sadd(name,values)
name - 对应的集合中添加元素
1
2
3r.sadd("set1", 33, 44, 55, 66) # 往集合中添加元素
print(r.scard("set1")) # 集合的长度是4
print(r.smembers("set1")) # 获取集合中所有的成员获取元素个数 类似于len
scard(name)
获取name对应的集合中元素个数
1
print(r.scard("set1")) # 集合的长度是4
redis基本命令 有序set
Set操作,Set集合就是不允许重复的列表,本身是无序的。
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
新增
zadd(name, args, *kwargs)
在name对应的有序集合中添加元素1
2
3
4
5
6
7
8
9
10
11
12import redis
import time
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.zadd("zset1", n1=11, n2=22)
r.zadd("zset2", 'm1', 22, 'm2', 44)
print(r.zcard("zset1")) # 集合长度
print(r.zcard("zset2")) # 集合长度
print(r.zrange("zset1", 0, -1)) # 获取有序集合中所有元素
print(r.zrange("zset2", 0, -1, withscores=True)) # 获取有序集合中所有元素和分数
管道(pipeline)
redis默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
1 | import redis |
管道的命令可以写在一起,如:
1 | pipe.set('hello', 'redis').sadd('faz', 'baz').incr('num').execute() |